인공지능이 만드는 폰트
HAN2HAN : Hangul Font Generation
서대문형무소서 보낸 서신

위 그림은 이연호 선생님이 서대문 형무소에서 보낸 서신을 '그새 학교잘 다니냐','나는 잘있다' 두 문장을 발췌하여 폰트를 생성한 예시글이다. 발췌한 문장에서 글자는 13글자이지만, '잘'과 '다'가 중복되어 사실 상 모델이 활용할 수 있는 글자는 11글자이다. 이연호 선생님 글씨체는 부드럽게 흘리는 것 같으면서도 깨끗한 느낌을 주는 것이 특징이다. 생성된 '8호 감방의 노래 <대한이 살았다>'를 보면 그 특징이 잘 살아있는 것을 확인할 수 있다. 특히 초성에서는'ㅎ'과 'ㅇ'이 특징을 잘 살린 것을 확인 할 수 있고,중성 및 종성에서 'ㄹ'과 'ㄴ'받침또한 특징을 잘 잡았다고할 수 있다. 반면 초성 'ㄷ'는 흐려지며 글씨체가 끊긴다는 점과, '그'라는 글씨체가 독특하다 보니 'ㅗ'를 잘 구현하지 못했다는 점이 확인된다.
알파벳으로 한글 구현

놀라운 점은 영어의 알파벳의 특징도 생각보다 잘 잡아낸 다는 것이다. 일부러 외국사이트에서 독특한 폰트를 가져왔다. 위는 크리스마스 기념 폰트로 글씨체위에 눈이 쌓여있는 형태이고 아래는 피가 흐르는 형태의 공포분위기의 폰트이다. 완벽하게 구현하는 것은 아니지만, 글씨체의 굵기나 필체의 부드러운 정도를 잘 따라하고 있다. 특히 위 폰트에서 에폭이 증가하며 점차 눈이 형상화되는 모습은 굉장히 놀라웠다.
다른 폰트들

위 4개의 폰트는 훈련에 사용되지 않은 폰트이다. 처음 보는 폰트임에도 불구하고 사람의 눈으로 구분이 힘들정도로 잘 생성되고 있는 것을 확인할 수 있다.
Architecture
Category Embedding
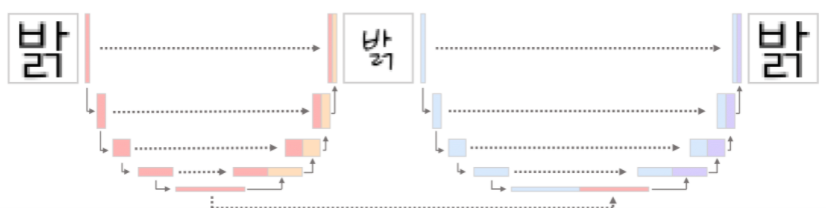
본 프로젝트에서 소스폰트는 어떤 글자인지 알려주는 'Condition'역할을 수행한다. 그렇기에 소스폰트는 어떤 스타일로든 변할 수 있어야하는 동시에 해당 글자의 특성을 잃지 말아야한다. 위 예시그림에서는 다른 스타일의 '밝'로도 변할 수 있어야 하는 동시에 '밝'이라는 글자의 특징을 잃어서는 안되는 것이다. 특징을 읽흐면 Condition의 역할을 하지 못한다. 소스폰트에서 스타일이 변한 글자를 다시 Reconstruct함으로써 해당 글자의 특징을 더 잘 유지할 수 있도록 하였다. 이러한 구조는 CycleGAN에서 영감을 받았다.
일반적으로 인코더의 마지막 임베딩 값을 카테고리 임베딩으로 사용한다. 하지만 이 모델은 하나만 사용하는 것이 아니라, 인코더 구조를 동일하게 해놓아 모든 레이어를 사용할 수 있도록 하였다. 즉, 소스폰트에서 인코딩한 값들(이미지에서 붉은색으로 칠해진 부분)이 폰트 생성시에 모두 반영된다.
Pix2Pix - Generator part
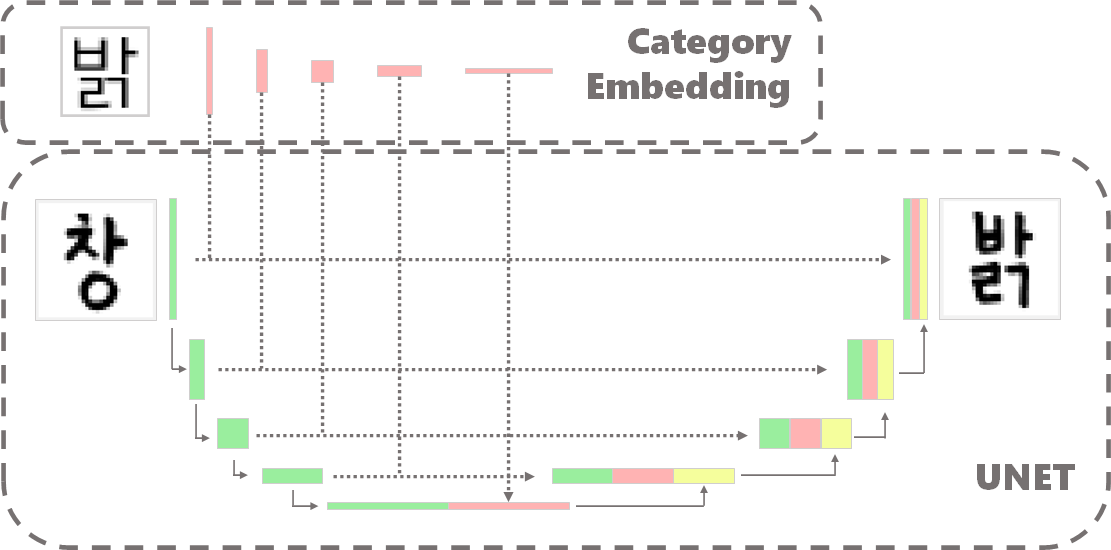
기존의 U-NET과 동일한 형태로 생성하게 되나 다른 점은 카테고리 임베딩이 추가된다는 점이다. 인코딩된 값은 뒷 단의 디코더 부분에서 연결(concatenate)되는데 이 떄 임베딩된 값들도 함께 연결된다. concat되는 값들을 정리하면 아래와 같다.
- 인코더에서 나온 feature map
- 이전단계에서 upconvolution한 feature map
- category embedding된 feature map
Pix2Pix - GAN Part

중요한 것은 다른 글씨체를 넣어도, 소스폰트가 임베딩 된 값에 따라 해당 글씨체로 훈련할 수 있어야 한다. 위 그림에서 '창'또는 어떤 글자가 들어가도 소스폰트가 '밝'이었을 때 생성자(Generator)는 '밝'을 생성해야한다. 판별자(Discriminator)는 단순히 0(True Image)또는 1(Fake Image)로 분류한다. 생성자는 판별자를 속이도록 훈련하고, 판별자는 진짜이미지를 골라내도록 훈련한다. 이미지의 사이즈가 32x32로 작아서 PatchGAN은 의미가 없다고 생각했다. 사전훈련된 모형은 네이버 나눔 폰트 138개를 학습하였으며 생성자 30에폭을 훈련시킨 뒤, 판별자 30에폭을 독립적으로 훈련시키고 30에폭을 함께 학습하였다.
Pretraining에서는 문제가 되지 않지만 Finetuning은 단지 10글자내외로 많은 글자를 만들어 내야 한다. 예를 들어 10글자를 Finetuning한다고 하였을 때, 각 글자는 9글자를넣어서 1글자를 만들어내는 것을 훈련한다. 즉, 10글자로 90번(10*9번) 훈련할 수 있다. 손실함수는 L1 Loss를 사용했으며, Learning rate를 4e-55e-5 정도로 배정하고 100200 epoch 훈련시켰을 때 경험적으로 좋은 결과를 나타냈다.
Character Embedding
예를 들어 10글자가 입력값으로 존재할 때, 소스폰트로 한 글자를 생성하기 위해서는 10가지 경우의 수가 생긴다. 무작위로 선정하여 생성할 수도 있겠지만, 그래도 조금은 연관성 있는 글자를 넣어서 출력하면 잘되지 않을까 생각에 AutoEncoder를 사용하여 글자별로 임베딩을하였다.
사실 이 부분에 있어서 기존의 인코더로 접근을 시도하였으나 U-NET 특성상 전의 레이어를 나중에 반영하기 떄문에 AutoEncoder가 더 적합한 모형이라고 생각했다. Clustering으로 접근을 시도했으나 이 부분에대해서는 추후에 고도화시키는 것으로 하고, 단순히 임베딩 된 값에대해 Cosine Similarity를 통해 매칭한다.
Strength
- 10글자 내외의 적은 숫자의 글씨만으로도 폰트가 생성 된다
- 일반화가 잘되는 것 처럼 보인다. 심지어 알파벳 넣어도 잘되고, 예시에서 본 것처럼 눈이 쌓인 폰트의 표현도 가능하다.
- 사용한 자원이 개인 연구 수준으로 비용이 적게든다. (Pretraining과 Finetuning 모두 Google Colab의 GPU를 사용함)
- 폰트를 디자인하는데 비용을 낮출 수 있다.
Weakness
- 깨지는 글자가 나타난다.
- 글자 수가 적다.
- 기존에 훈련된 데이터에서 형식이 많이 벗어나면 데이터가 있는 것이 오히려 악영향을 미친다. (서대문 형무소서 보낸 서신또한 '그'라는 글자가 없는 것이 오히려 깨지는 글자가 더 적어진다.)
- 첫 번째 이유와 두 번째 이유가 상충하는데, 결론적으로는 '일관된 글씨체'의 데이터가 필요하다고 사료된다.
- 생성할 수 있는 글자는 2420글자로 제한되어있다.
- 138폰트의 2420글자로만 훈련을 해서 생성할 수 있는 글자가 2420글자로 제한되어있다.
- 11,172자와 더 많은 폰트로 pretraining을 진행 한다면 더 좋은 성능이 기대된다.
- 138폰트의 2420글자는 글자별로 군집하기에 너무 작은 양이다. 더 많은 글자를 훈련한다면 캐릭터 임베딩이 더 효과를 볼 수 있을거라고 생각한다.
- 반면, 생성해야하는 글자가 많아져 카테고리 임베딩이 더 힘들 수 이어질 것이라고 생각한다.
- 폰트의 갯수를 늘리는 것이 더 중요하다고 생각한다.
- 138폰트의 2420글자로만 훈련을 해서 생성할 수 있는 글자가 2420글자로 제한되어있다.
- 32x32라는 작은 사이즈의 이미지로 학습하고 생성하여 실제 서비스로 가기까진 품질이 떨어짐
- 추후에 자원을 더 많이 사용해서 보다 큰 사이즈로 훈련시킨다면 고품질 폰트를 생성할 수 있을거라고 생각한다.
- 캐릭터임베딩의 효과를 입증하지 못했다.
- 결과는 매칭시키는 게 더 좋아보이기는 하나 수치적으로 입증하지 못했다.
- 코사인 유사도로 매칭시켜서 생성하는데, 이걸 좀 더 고도화한다면 효과가 더 좋지 않을까 생각한다.
- discrepancy
- 훈련시킨 것은 디지털 폰트인데 생성하는 것은 카메라 등의 이미지로 생성한다면 discrepancy발생
- 디자인 된 폰트는 대부분 일정한 글씨체를 가지나, 실제 사람은 때때로 본인 스타일과 다른 글씨체를 쓰는 경우가 있어 discrepancy발생
- 그러나 '서대문 형무소서 온 서신' 예시와 같이 글자를 생성 이전에 전처리를 통해 '폰트화'시켜주면 생성 성능에 큰 지장은 없음
GitHub - MINED30/HAN2HAN: Hangul Font Generation
Hangul Font Generation. Contribute to MINED30/HAN2HAN development by creating an account on GitHub.
github.com
'인공지능 > CV' 카테고리의 다른 글
| [논문리뷰]Dall-E : Zero-Shot Text-to-Image Generation (0) | 2022.07.01 |
|---|---|
| [논문리뷰] CoCa: Contrastive Captioners are Image-Text Foundation Models (0) | 2022.06.06 |
| GAN에서의 미분 (Pytorch) (0) | 2021.10.13 |
| YOLOv3를 이용한 턱스크찾기 프로젝트 (3) | 2021.05.01 |
| 객체탐지 (Object Detection) 2. YOLO !! (v1~v3) (2) | 2021.05.01 |




댓글