백지장도 맞들면 낫다, 앙상블 OVERVIEW
Ensemble
앙상블 Ensemble
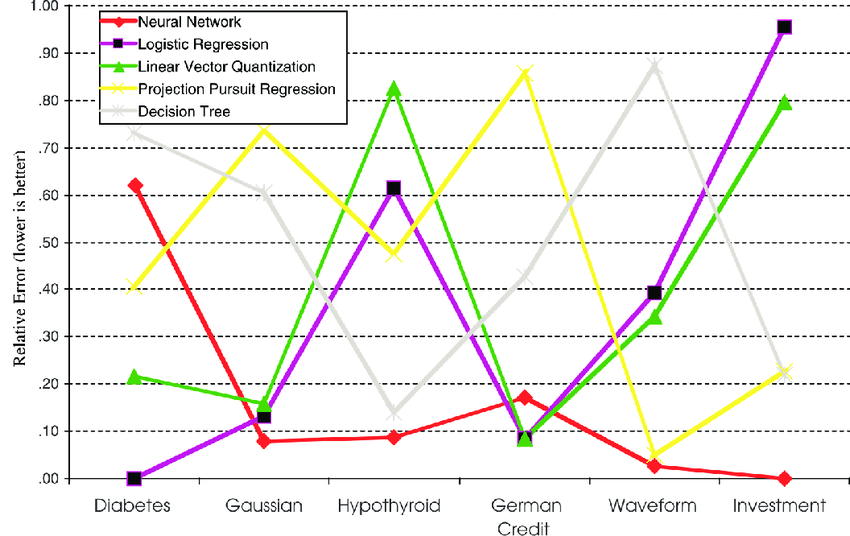
모든 데이터에서 가장 좋은 성능을 내는 모델이 있을까요? 지금까지 연구자들이 낸 답은 '없다' 입니다. 각 데이터마다 모델의 성능이 제 각각이기 때문입니다. 위 그림은 각 모델들의 데이터셋 별 성능입니다. 정말 제 각각입니다. 데이터 셋마다 그 순위가 다 다릅니다. 정말 다른 모델을 압도하는 이상적인 모델은 없을까요? 아마 그런 모델은 앞으로도 나오기 힘들것 같습니다. 그럼 모델끼리 합친 성능은 어떨까요?
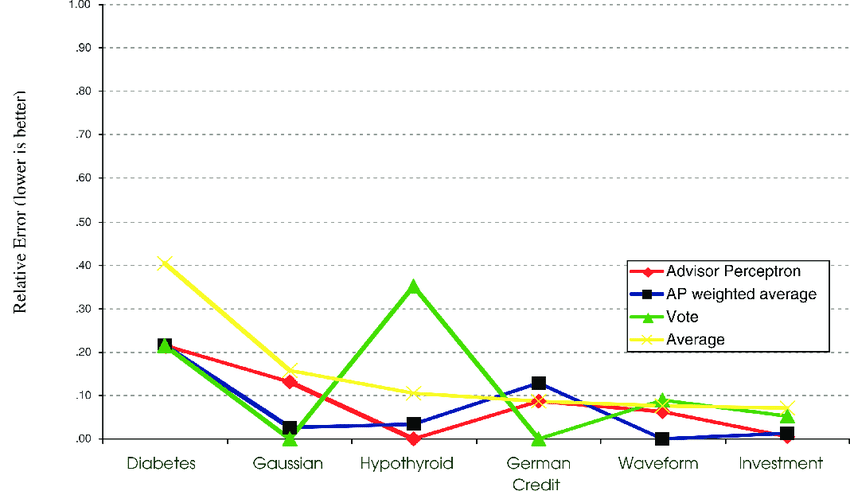
오차가 전체적으로 주는 것을 볼 수 있습니다. 모델들이 서로 잘 조합된다면 단일모델들보다 더 좋은 성능을 보장할 수 있습니다. 모델을 합치는 것을 앙상블기법이라고 합니다. '앙상블'이란 전체적인 어울림이나 통일. ‘조화’로 순화한다는 의미의 프랑스어입니다(wikipedia). 잘 어울린다면, 조화를 이룬다면 더 좋은 성능을 낼 수 있는 아주 중요한 기법입니다 !


정말 모델을 합치는 것만으로 오차를 줄일 수 있을까요? 위 두 그림은 모델의 수에 따른 오차를 나타낸 차트입니다. 모델의 수를 합칠 수록 모델의 오차가 단계적으로 내려가는 모습입니다. 전체적으로 오차가 우하향하는 것을 확인할 수 있습니다. 앙상블은 '단일모델'보다 '대부분' 성능이 더 좋았습니다.
'대부분' 성능이 더 좋다.

위처럼 도출해보면, 이론적으로는 앙상블이 단일모델의 오차의 1/M이 됩니다! 하지만 error간에 전혀 상관관계가 없어야합니다. 이는 현실적으로는 가능하지가 않겠죠. 현실에서는 어떨까요? Cauchy–Schwarz inequality(코시-슈바르츠 부등식)으로 도출할건데 코시슈바르츠 부등식은 ${(a^{2}+b^{2})}{(c^{2}+d^{2})}$≥${(ac+bd)}^{2}$입니다.

그럼 위의 식을 이해할 수 있습니다! 결론은 상관관계가 있는 에러값이라도, 앙상블의 평균오차는 단일모델의 평균오차보다 작다는 것을 알 수 있습니다. 최소한 중간정도의 성능은 한다는 의미가 됩니다.
Bias-Variance Decomposition 편향과 분산


Cost Funstion가 MSE일때를 보겠습니다. 왼쪽 식을 제곻배서 풀게되면 오른쪽과 같은 식이 됩니다. 이 식을 잘 들여다보면, 예측치의 기댓값에서 실제값을 뺀 뒤에 제곱을 하는것은 Bias(편향)입니다 ! 에측치에서 예측치의 평균을 빼면 이는 Variance가 됩니다 ! 다시말해서 위 식은 아래로 쉽게 표현할 수 있습니다.
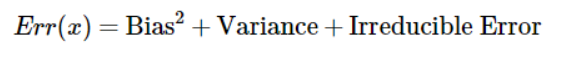
위 식이 의미하는 것은 무엇일까요?

잠깐 위그림을 봅시다. Overfitting된 모델로 새로운 데이터를 예측하게 되면 오차는 각각 다르게 나타나고 퍼지게 될 것입니다. Underfitting된 모델로 새로운 데이터를 예측하게 되면 한쪽으로 치우치게 될 것입니다. 이를 그림로 나타내면 다음과 같습니다.

이는 모델의 복잡도에 따라서 달라집니다.
복잡도가 낮은 모델은 High Bias & Low Variance를 가집니다.
복잡도가 높은 모델은 Low Bias & High Variance를 가집니다.
Lower Complexity & High Bias & Low Variance를 가진 모델로는
- Logistic Regression, LDA, K-NN with large K 등이 있습니다.
Higher Complexity & Low Bias & High Variance를 가진 모델로는
- Decision Tree, Support Vector Machine, K-NN with small K 등이 있습니다.
정리하면, 에러를 줄이는 방법에는 두가지가 있습니다. 하나는 Variance를 줄이는 방법이고, 다른하나는 Bias를 줄이는 방법입니다. 우리는 앙상블 기법을 통해서 위 에러를 줄일 것입니다.
- Variance(분산)을 줄이는 방법 : Bagging, Random Froests
- Bias(편향)을 줄이는 방법 : AdaBoost
- Both : Mixture of experts
The ensemble construction
1. Sufficient degree of diversity
2. How to combine
똑같은 모델을 여러개 만들어 봤자 합쳐도 아무런 의미가 없습니다. 각 모델은 똑같은 결과를 낼 것이고, 그에대한 오차는 감소하지 않을 것이기 때문입니다. 그럼 어떻게 각 모델이 충분히 다양하게 만들 수 있을까요? 무작정 다르게만 만드는 것은 안됩니다. 두가지 중요한 요건이 있습니다.
첫 번째는 달라야한다는 것이고,
두 번째는 각 모델의 성능이 꽤 괜찮아야한다는 것입니다.
위의 조건을 만족시키는 두가지 방법이 있습니다.
하나는 데이터셋을 다르게 주어서 학습을 시키면 다른모델이 만들어 질 것이라는 생각에서 나온 방법(Implicit, Independent),
다른하나는 아예 지표를 주어서 이전 모델과 다르게 만들도록 유도하는 방법(Explicit, Model guided)이있습니다. 아래는 이를 도식화하여 나타낸 그림입니다.

Independent instance selection은 Training Set에서 각각의 모델을 만들고있고, Model guided instance selection은 Training Set에서 한 모델을 만들고, 그 모델에서 나온 지표를 적용하여 새로운 모델을 만들고 있음을 볼 수 있습니다.
참고자료
(PDF) The Generalization Paradox of Ensembles
PDF | Ensemble models—built by methods such as bagging, boosting, and Bayesian model averaging—appear dauntingly complex, yet tend to strongly... | Find, read and cite all the research you need on ResearchGate
www.researchgate.net
Understanding the Bias-Variance Tradeoff
Whenever we discuss model prediction, it’s important to understand prediction errors (bias and variance). There is a tradeoff between a…
towardsdatascience.com
pilsung-kang/Business-Analytics-IME654-
Course homepage for "Business Analytics (IME654)" @Korea University - pilsung-kang/Business-Analytics-IME654-
github.com
'인공지능 > 앙상블' 카테고리의 다른 글
| [Ensemble] XGBoost, 극한의 가성비 (2) | 2021.02.14 |
|---|---|
| [Ensemble] Gradient Boosting, 차근차근 (0) | 2021.02.12 |
| [Ensemble] Ada Boost, 모델의 오답노트 (0) | 2021.02.11 |
| [Ensemble] 랜덤 포레스트, 나무가 이루는 숲 (0) | 2021.02.11 |
| [Ensemble] 배깅, 언제나 처음처럼 (2) | 2021.02.10 |




댓글