Ada Boost, 모델의 오답노트
Ensemble
지금까지 앙상블 기법에서 배깅에대해 다루어 보았습니다. 이제 Boost에대해 알아보겠습니다. Bagging이 데이터셋을 새롭게하면서 다양성을 부여했다면, 부스트는 모델을 하나 만들고, 그 모델을 지표로 다른 모델을 만들어 다양성을 부여하는 방법입니다. 이 포스트는 지난 포스트에 기반하여 작성되었습니다.
[Ensemble] 백지장도 맞들면 낫다, 앙상블 OVERVIEW
백지장도 맞들면 낫다, 앙상블 OVERVIEW Ensemble 앙상블 Ensemble 모든 데이터에서 가장 좋은 성능을 내는 모델이 있을까요? 지금까지 연구자들이 낸 답은 '없다' 입니다. 각 데이터마다 모델의 성능
exupery-1.tistory.com
Adaptive Boost
1과 0이 반반씩 섞여있는 데이터에서 하나로 찍으면 확률이 50%는 될 것입니다. 이를 Random Guessing이라고하고, 이보다는 살짝 더 잘맞추는, 하지만 이 모델만 가지고 사용할 수는 없는 모델을 Weak Model이라고 합니다. 이 Weak Model을 모아서 새로운 모형을 만들 것 입니다 !
랜덤포레스트도 이와 같은 컨셉이지만, 다른점은 랜덤포레스트는 Parallel하게 각각의 모형들이 답을 도출합니다. 그리고 투표(Voting)같은 방법으로 의견을 취합(Aggregating)하게 됩니다. 반면 Adaptive Boost는 틀린문제만 보는 것입다. A라는 모델이 문제를 먼저 풀고, 틀린것에 가중치를 둬서 B모델이 학습합니다. C모델은 A와 B가 틀린문제에 가중치를 둬서 문제를 풀고, 이게 쭉 이어지면 웬만한 문제는 맞출 수 있겠다는 컨셉입니다. Parallel은 되지 않겠죠?
Overview에서 Boosting기법은 Bias를 줄이는데 효과적이기 때문에 Lower Complexity & High Bias & Low Variance를 가진 모델과 궁합이 잘 맞는다고 했습니다. Logistic Regression, LDA, K-NN with large K이 있었습니다. 단순한 모델을 여러번 사용하여 학습시킵니다.
Bagging vs Boosting
배깅과 부스팅 모두 복원추출을 합니다. 배깅은 모든 변수가 뽑힐 확률이 같습니다. 예를들어 데이터(관측치)가 5개가 있으면 각각이 뽑힐 확률은 0.2로 동일합니다. 부스팅도 처음에는 이렇게 시작합니다. 하지만 알고리즘을 통해서 뽑히는 확률이 변하게 됩니다.
정리하면, Bagging은 랜덤하게 전체 데이터에서 항상 같은확률로 뽑게되고
Boosting은 Sequential하게 잘 못맞춘 데이터에 뽑힐 확률을 높여주게 됩니다.
아래에 알고리즘에서 더 자세하게 설명하겠습니다.
Algorithm

분류문제에서 Adaptive Train에서는 0과 1로 나누는게 아니라 -1과 1로 나눕니다. 이유는 뒤에서 설명하겠습니다.
. t가 1부터 T까지 반복합니다.
. (t=1부터) D1부터 시작합니다.
- 가설함수 $h_1$에 D1을 통해 학습합니다. 여기서 $h_t$는 보통 Stump tree를 씁니다. (Stump 트리란 딱 한번만 나누어 분류하는 모델입니다. stump는 나무 밑둥이라는 뜻이있습니다.) Stump tree는 굉장히 Weak Model입니다.
- 학습된 모델에서 오분류한 값을 계산합니다.
- 0.5미만으로 맞췄을 경우 다음단계로 넘어갑니다. Random보다 낮으니 Weak Model로서의 역할도 못한다고 판단되어 빼주는 것입니다.
- $a_t$는 틀린 것에 줄 가중치입니다. 가중치를 계산합니다. 오분류가 0.5이라면면 대입해보면 가중치가 0에 가까워집니다. 오분류가 작을 수록 가중치는 높아집니다. 잘맞춘 모델일 수록 다음 모델이 못맞춘 값에대해 집중해서 문제를 풀 거란 뜻입니다.
- $D_2$를 업데이트시켜줍니다. 식을보면 $a_t$에 -가 붙어있는데, sampling rate의 변동성을 크게 해줄 것이라는 소리입니다. 다시말해 $h_t$가 잘맞추는 모델인데 $D_{t}(i)$도 맞췄으면 선택할 확률을 급격하게 낮춰줄 것이고($h_t$잘맞추면 $a_t$가 크므로), 잘맞추는 모델인데도 못맞췄으면 선택확률을 급격하게 증가시켜줄 것이라는 뜻입니다.
$y_i$와 $h_{t}(x_{i})$를 곱해주어서 맞추었으면 1 (1 * 1 = 1 or -1 * 1 = -1), 틀렸으면 -1 (-1* 1 = -1, 1*-1 = -1)이됩니다. 앞서말한 y의 예측치를 1과 -1로 나누는 이유가 여기에 있습니다. 즉, 정리하면 맞추면 앞에서 -가 있으니 음수값이나오므로 선택될 확률을 줄여줄 것이고, 맞추지 못했으면 양수가 되므로 선택될 확률을 증가시킵니다. - 이렇게 가중치를 구한 것으로 최종 예측에 반영하겠다는 뜻입니다.

첫번째에는 오분류된 것은 +가 3개가 있습니다. +가 틀렸으므로 이 변수는 선택될 확률이 증가하게됩니다.
두번째에서는 -3개를 틀리고, 앞서 틀린 +3개는 맞췄습니다 ! 그럼 맞춘것은 선택될확률이 줄고, 틀린것은 증가합니다. 세번째에서는 연속으로 2번 맞춘 왼쪽의 + 2개는 크기가 작아졌고, 두번째에서 커졌던 +가 작아지고 틀린 -가 커진 것을 확인할 수 있습니다. 이렇게 모델을 조정하고 결국에는 마지막에 BOX4를 최종 모델로 내게됩니다.
단순한 모델로도 복잡한 모델로 만들 수 있습니다.
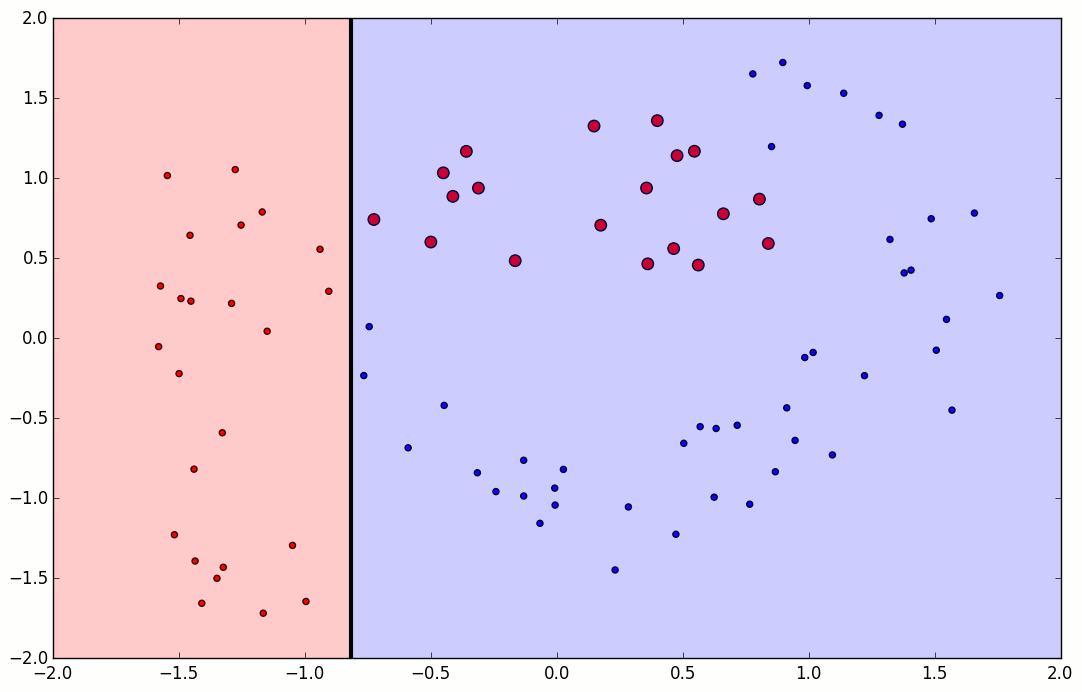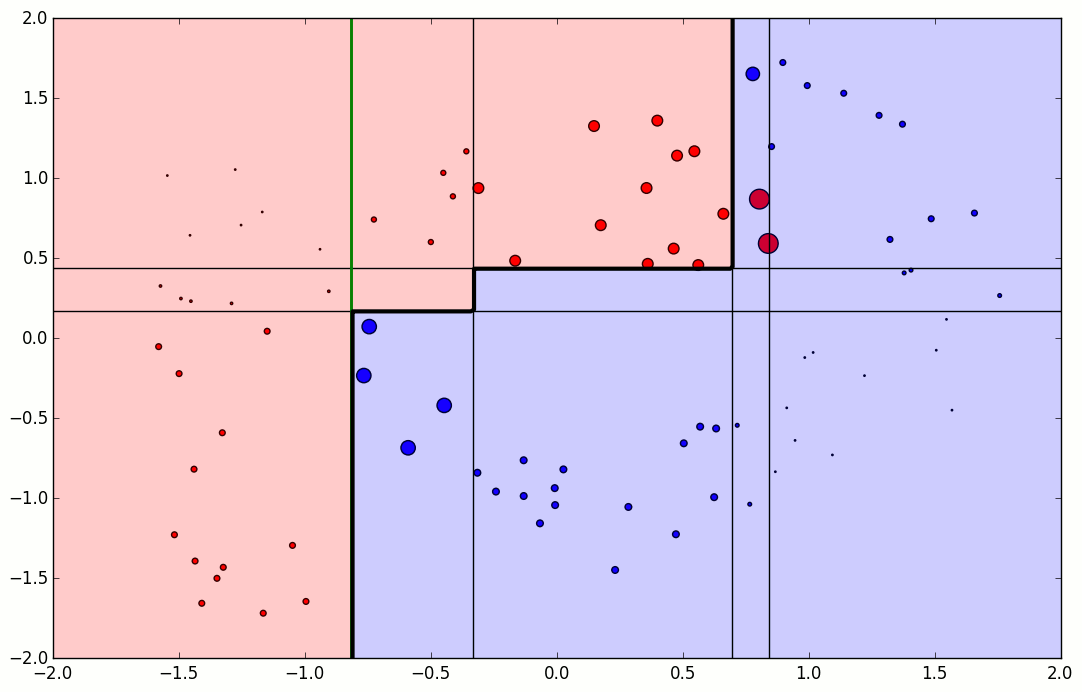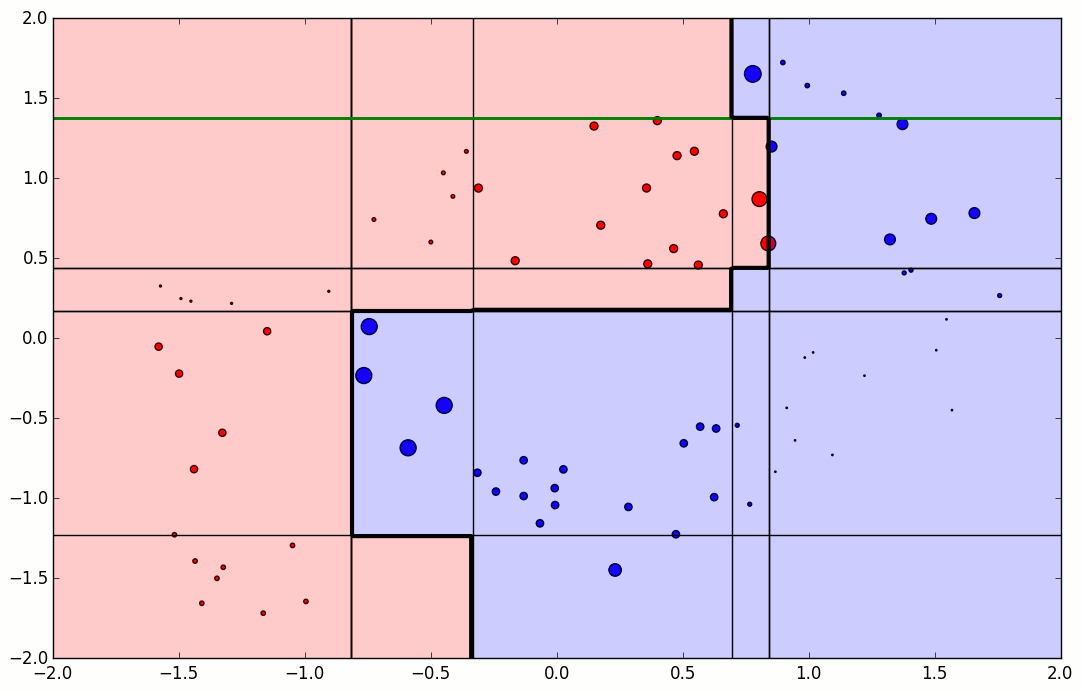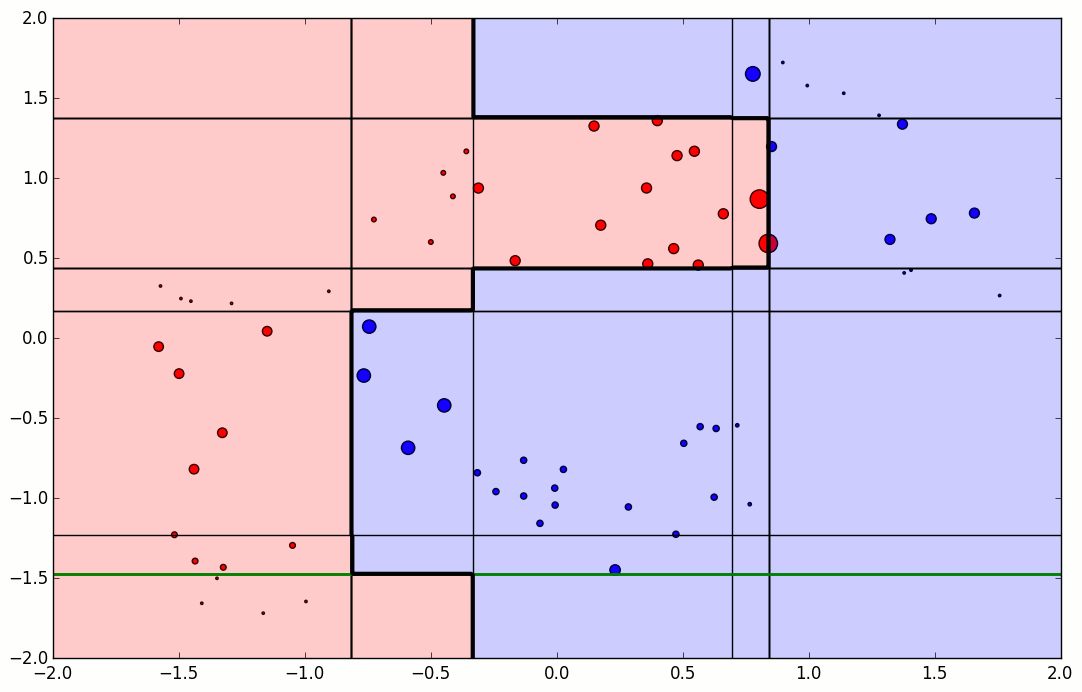
틀린 것에대해 크기가 커졌다 줄었다하는 것을 볼 수 있습니다.
참고자료
AA-12
aa.ssdi.di.fct.unl.pt
Understanding AdaBoost
Anyone starting to learn Boosting technique should start first with AdaBoost or Adaptive Boosting. Here I will try to explain it…
towardsdatascience.com
pilsung-kang/Business-Analytics-IME654-
Course homepage for "Business Analytics (IME654)" @Korea University - pilsung-kang/Business-Analytics-IME654-
github.com
'인공지능 > 앙상블' 카테고리의 다른 글
| [Ensemble] XGBoost, 극한의 가성비 (2) | 2021.02.14 |
|---|---|
| [Ensemble] Gradient Boosting, 차근차근 (0) | 2021.02.12 |
| [Ensemble] 랜덤 포레스트, 나무가 이루는 숲 (0) | 2021.02.11 |
| [Ensemble] 배깅, 언제나 처음처럼 (2) | 2021.02.10 |
| [Ensemble] 백지장도 맞들면 낫다, 앙상블 OVERVIEW (0) | 2021.02.10 |




댓글