
Recipes for building an open-domain chatbot
paper url : https://arxiv.org/pdf/2004.13637.pdf
본 논문은 Facebook에서 발표한 Open Domain Chatbot에 관한 내용이며, 구글에서 발표한 Open Domain Chatbot인 Meena를 많이 의식하고있는 것 같다. 흥미로웠던 점은 단순히 대답을 하는 것에 초점을 맞춘 것에서 벗어나 '좋은 대화'가 무엇인지부터 논의했다는 점이다. 데이터셋이 모델의 먹이라면, 좋은 대화를 만들어내기위해 정말 다양하면서도 질 좋은 먹이를 준다. 그리고 이 먹이를 어떻게 잘 섞는지 방법도 소개한다. 문장을 생성하기위해 크게 두가지 방법을 사용했다. 검색모델과 생성모델이 그 것인데, 이 둘의 장점 모두를 끌어내기위한 아이디어를 소개한다. 이 부분을 잘 활용한다면 더 확장시켜 모델을 개선할 수 있을 것 같다는 생각도 든다.
본 포스트에서는 매력적이고, 대화가 끊이지 않게 화두를 던지기도하며, 전문적이기도 하며, 공감능력을 가지는 챗봇을 만드는 레시피를 소개하고자한다.
Model Architecture 모델구조
본 논문에서는 트랜스포머를 사용한 3가지 아키텍쳐를 소개한다
Retriever 검색 모델
대화기록(Context)을 입력으로 넣어줄 때, 모델은 답변이 될 여러개의 후보 중에서 '좋은 답변'을 잘 고를 수 있어야한다. Retrieval system은 다음 대화의 Utterance를 골라야된다.
Bi encoder
Context문장과 Candidate문장과 따로 임베딩을 시킨다. 그러면 Context Embedding과 Candidate Embedding 두개가 따로 나온다. 따로 나온다는 것이 Bi-encoder의 가장큰 장점인데, 한번 임베딩한 Candidate는 저장해서 또다시 임베딩할 필요가 없기 때문이다. 물론 Attention할 때 context와 candidate가 별도로 수행되니 아래의 Cross Encoder보다 성능은 떨어질 수 밖에 없다.
Cross-encoder
Cross encoder는 input과 context데이터를 Concat해서 입력한다. 위에서 말했듯 Attention이 Context와 Candidate가 함께 진행이 되기 때문에, 보다 연관성있는 임베딩이 가능하다. 하지만 그만큼 inference 속도가 느려진다는 단점도 있다.
Poly-Encoder
둘의 장점을 취하는 구조이다. 크게 3개의 어텐션과정으로 이루어져있다.
첫번째 어텐션은 Candidate Encoder에서 이루어진다. 기존 Bi Encoder처럼 별개로 연산이 이루어져 Candidate Embedding을 별도로 취할 수 있다.
다음으로 Context Encoder에서 N개의 값을 출력하면, 이 값으로 두 번째 Attention이 이루어진다. 이 때 쿼리는 finetuing으로 훈련된 코드 값으로 날린다. 훈련전에는 랜덤 이니셜라이징한다. 쿼리 코드는 m개(하이퍼파라미터)로 정한다. 즉, m개의 코드 값으로 쿼리를 하여 Attention을 수행하고 아웃풋으로 m개가 출력이 된다.
마지막으로 이 m개의 값을 Key, Candidate Embedding을 Query로 세 번째 Attention을 수행한다. 출력은 Context Emb가 된다.
정리하자면 (1) Bi Encoder처럼 별도로 Candidate Encoding을 실시하고, (2) Context Emb를 최종적으로 출력하기 전에 Key를 만들어주어 (3) Cross Encoder같이 Context Emb을 출력할 때 Candidate의 정보가 반영이 될 수 있도록 만든 구조이다.
마치 CV 객체탐지에서 FastRCNN의 개념이 비슷하다. 이미지에서 ROI마다 각각 컨볼루션시키는 것보다 이미지 자체를 컨볼루션을 시켜서 Feature map을 한번 만들고 ROI를 뽑는게 더 빠르다.
Cross Encoder는 두 개의 입력 그대로에서 결과를 내는 과정이라면 Poly Encoder는 먼저 특성을 추출한 뒤에 합친다고 생각하면 좀 더 직관적인 이해가 될 것 같다.
Generator 생성기
위에서 폴리인코더를 사용해도 해결하지 못하는 문제가 있다. Retrieval System자체의 한계인데, Candidate 셋에서만 대답을 뽑을 수 있다는 점이다. 그래서 직접 생성을 할 수 있어야한다. 본 논문에서는 파라미터 수가 90M, 2.7B, 9.4B인 3가지 크기의 모델을 시도했다. 생성모델은 트랜스포머를 차용했다.
위 테이블을 보면 상대적으로 작은모델(90M)을 제외하고는 (Encoder Layer)보다 (Decoder Layer)의 수가 더 많은 것을 볼 수 있다. 그만큼 Generative Model은 Decoding에 더 많은 초점을 두었다.
Generative Model이 생성하는 대답은 짧은 문장으로 말하려는 경향이 있거나, 너무 일반적인 대답(매력도가떨어지는대답)을 하고, 반복된 대답을 하는 등 여러가지 한계가 존재하였다.
Retireve & Refine 검색한 것을 바탕으로 생성하기
Retrieval Model과 Generative Model이 갖고 있는 한계를 극복하고자한다. 접근방법은 Generation하기 전에 Retrieval step을 먼저 진행하고 반영하는 것이다. 이해를 돕기위해 도식을 나타낸 유튜브영상을 첨부한다. 여기서 Poly-Encoder는 Retrieval Model이며 Decoder는 Generative모델이다.
- Dialogue Retrieval
주어진 대화기록(Context, 입력문장)으로 Retrieval Model은 Candidateset에서 찾아 답변을 생성한다. Retrieval Model은 Generation모델보다 덜 일반적(Candidate에서 뽑으니까)이고 지엽적이므로 이를 활용하면 Generative Model의 한계를 개선할 수 있다고 주장한다. 단순히 입력값과 Retrieval Model로 찾은 답변을 [SEP]토큰을 두고 CONCAT시켜서 디코더에 넣는다. (Decoder가 훈련될 때 Retrieval Model이 Inference한 결과를 거의 무시하는 현상도 나타났는데, 뒤에서 논한다.)
- Knowledge Retrieval
WoW task를 수행한다. 위키를 통해서 보다 전문적인 대답을 할 수 있도록 진행하는 것이다. 언제 WoW task를 수행할지 지도학습을 시켰다. Wikipedia dump(WoW 데이터)를 통해서 TF-IDF기반으로 인덱스를 찾는다. Retrieval Model이 candidate의 랭킹을 매기고 결과를 낸다.
Training Objectives
Ranking for Retrieval Poly-Encoder를 사용하여 Retireval의 순위를 매겼다.
Likelihood Training for Generation Greedy와 BeamSearch 알고리즘을 사용하고자하면 Maximum Likelihood Estimation 최대우도법으로 훈련시키는 것이 일반적이다. Negative Log Likelihood를 사용해서 이 값을 최소화시키는 방법을 사용했다. 문제는 반복적인 값들이 많이 너무 나오고 다양성이 부족하다는 점이다. 또한 긴 문장을 생성할 때 어색하게 만들기도한다. (구글의 Meena는 이러한 이유로 Greedy나 BeamSearch를 사용하지 않고 Sampling하는 방법을 사용했다고한다.)
a-blending for Retrive and Refine Retrieval이랑 Generative를 어떻게 블렌딩시킬 것이냐. 단순히 붙여서 MLE로 훈련시킨 결과, Generator는 Retrieve Model이 예측한 값을 그냥 무시하고 출력하여 성능이 좋지 못했다. 단순히 붙여서는 Retrieval Model이 예측한 내용이 반영이 안된것이다. 확실히 반영하기위해서 알파블랜딩을 시작했다. 전체 라벨 중 알파%만큼 Retrive 라벨로 대체하는 것이다. 즉, Retrieved의 대답으로 라벨을 대체한 것. 여기서 알파는 하이퍼파라미터다.
Unlikelihood training for generation 자주나오는 토큰을 Likelihood Maximization 훈련을 통해 얻을 수 있었다면, 그럴싸하지 못한 Unlikelihood를 추가한다. 앞서 말했듯이 Likelihood는 빈번하게 나오는 말에 확률을 과하게 부여해서 Overrepresent시키는데, 반복되는 Term에대해서 낮은 확률을 갖도록 강제하는 방법으로 영향을 줄여줄 수 있다. (인용된 논문의 제목도 'Don't Say That!'으로 시작한다.) 단순선형회귀에서의 Lasso, Ridge같은 느낌인데, 쉽게말해 Unlikelihood은 페널티를 주는 것이다. 식도 MLE로스에 Unlikelihood을 더해준다. Lasso의 람다가 하이퍼파라미터듯이, 얼마큼 페널티를 줄지는 알파()로 정한다. Likelihood가 gold candidate 토큰을 포함할 확률을 높여준다면, Unlikelihood는 negative token의 확률을 낮춰주는 효과를 볼 수 있다. Beam의 가장 치명적인 단점을 극복하고자하는 시도인 셈이다.
Decoding 생성모델에서의 디코딩 전략
Beam Search 빔서치 탐색 알고리즘 사용
흔히 Decoding에는 Greedy Algorithm과 Beam Search Algorithm이 많이 사용된다. Greedy는 매 순간 최선의 선택을 하는거고
Beamsearch는 Beam Size(k)를 잡고 나올 것같은 후보들 여러개(k개) 뽑아놓는다.
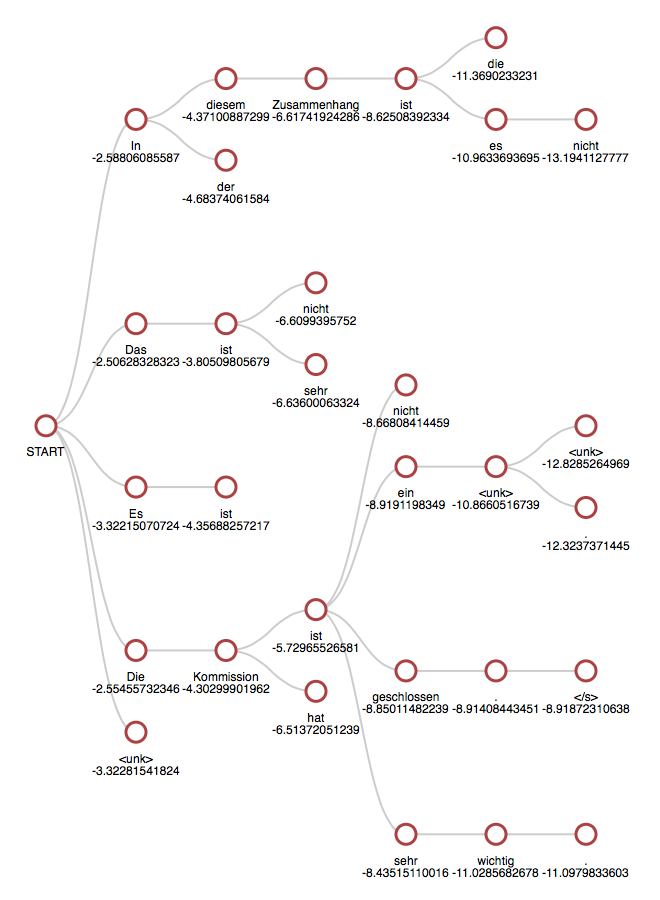
위 이미지는 k=5로 설정했을 때의 그림이다. START 뒤에 올 수 있는 것들 중 가장 유력한 5개를 뽑는다. 그리고 각각에 뒤에 올 수 있는 유력 후보를 뽑는데, 5개를 초과해서 저장하진 않는다. 후보를 5개만 남기고 다른 것을 지운다.
Sampling을 통해 top-k 와 Sample-and-Rank(Google Meena)를 사용하기도 하였는데 본 포스트에서는 생략한다. (구글 Meena에서는 Sampling이 Beam Search보다 좋다고 주장하는데, Facebook 에서는 이에 대항하여 강화된 빔서치는 샘플링보다 더 좋을 수 있다는 것을 주장한다)
Response Length 답변길이를 제한
디코더는 짧게 생성하려는 경향이 있기 때문에 길이 수를 제한하였다.
- Minimum Length 최소길이
<END>토큰이 이 Minimum Lenght 전에는 생성이 되지 않도록하여서 강제적으로 길이를 늘렸다. - Predictive Length 길이자체를 예측
(e.g., < 10, < 20, < 30, or > 30 tokens)
Predictive lengh를 4분류로 나눠서 길이 자체를 예측했는데, 너무 복잡해진다는 것이 단점이었다.
Training Data
Pre-training
- Reddit
BERT는 위키랑 토론토 북으로 훈련을 시키는데, 목적에 맞는 데이터셋으로 훈련을 시키면 더 좋은 성능을 이룰 수 있다.
그래서 본 연구에서는 사전훈련자체를 Reddit으로 학습시켰고, 훨씬 뛰어난 성능을 보였다. 전처리는 9개로 휴리스틱 룰을 정해서 사용했다. 그럼에도 톡식, 노이즈, 그룹디스커션 등 문제가 남아있다.
Fine-tuning
Pretrain을 위한 데이터인 Reddit은 그룹디스커션이지, 1대1대화가 아니다. 좋은 컨텐츠가 많음에는 분명하지만, 필터링을 하더라도 노이즈가 많다. 반면에 학술적인 자료(논문으로 발표된 데이터셋이라던지)는 숫자는 적을지라도 깨끗하고, TASK에 집중할 수 있다.
- ConvAI2
Personality(인간성), Engagingness(참여도)에대한 데이터셋이다. 서로 모르는 두 명에게 각자 페르소나를 주고, 그 역할에 맞춰 서로를 알아가는 대화로 구축이 되어있으며 14만개의 uttrance를 포함하고 있다.
- Empathetic Dialogues (ED)
Empathetic(감정, 공감)에대한 데이터셋이다. 대화중에 공감하는 내용이 담겨있다.
- Wizard of Wikipedia (WoW)
Wikipeia를 기반으로 깊이있는 대화, 전문적인 대화로 이루어진 데이터 셋이다. 모든 것을 아는 Wikipedia의 마법사와 호기심이 많은 견습생의 대화로 이루어져있으며, Wizard를 Bot으로 대체하는 것이 목적이다.

- Blended Skill Talk
앞선 3가지의 데이터셋을 잘 섞을 수 있는 것에 초점을 맞췄다. 데이터셋은 7만6천개의 uttrances를 포함하고 있고, guided speaker와 unguided speaker가 정해져있다. ConvAI와 같이 각 Speaker에대해서 페르소나가 주어지고 Topic이 주어진다. 위 Figure에서는 WoW topic이 주어진 뒤에 대화가 생성된다. Blended Skill Talk에 대한 내용은 별도로 포스팅을 하였다. (아래)
모든 대화 스킬을 한번에 ! Blended Skill Talk, Can You Put it All Together: Evaluating Conversational Agents’ Ability
Can You Put it All Together: Evaluating Conversational Agents’ Ability to Blend Skills https://arxiv.org/pdf/2004.08449.pdf Being engaging, knowledgeable, and empathetic are all desirable g..
exupery-1.tistory.com
Evaluation Methods
- ACUTE-Eval
사람에게 직접 평가하도록하였고 질문은 다음과 같다.
(1) 매력도 : 어떤 챗봇과 더 대화하고 싶은가
(2) 인간성 : 어떤 챗봇이 더 사람같은가 - Self-Chat ACUTE-Eval
사람이 직접 평가하는 것은 시간과 비용이 들기 때문에, chatbot끼리 대화를 평가하게 했다.
Results & Analysis
결과 분석에대한 내용은 별도 포스팅하였다.
https://exupery-1.tistory.com/218?category=980110
페이스북의 챗봇 레시피 Results & Analysis
Recipes for building an open-domain chatbot [Results & Analysis] paper url : https://arxiv.org/pdf/2004.13637.pdf 1. Automatic Evaluations Retriever 검색모델을 평가하는 데 있어서는 2가지 크기모델..
exupery-1.tistory.com




댓글