
Recipes for building an open-domain chatbot
[Results & Analysis]
paper url : https://arxiv.org/pdf/2004.13637.pdf
1. Automatic Evaluations
Retriever
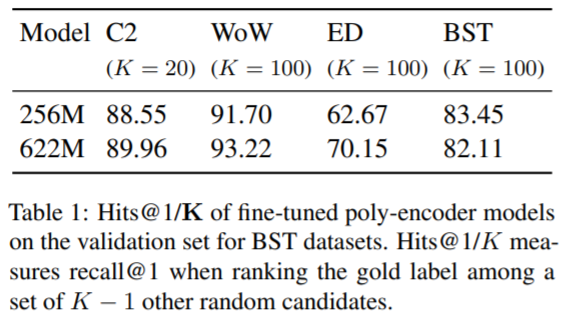
검색모델을 평가하는 데 있어서는 2가지 크기모델을 비교하였으며 결과는 파라미터가 큰 것이 대부분의 데이터셋에서 성능이 좋았다.
Generator

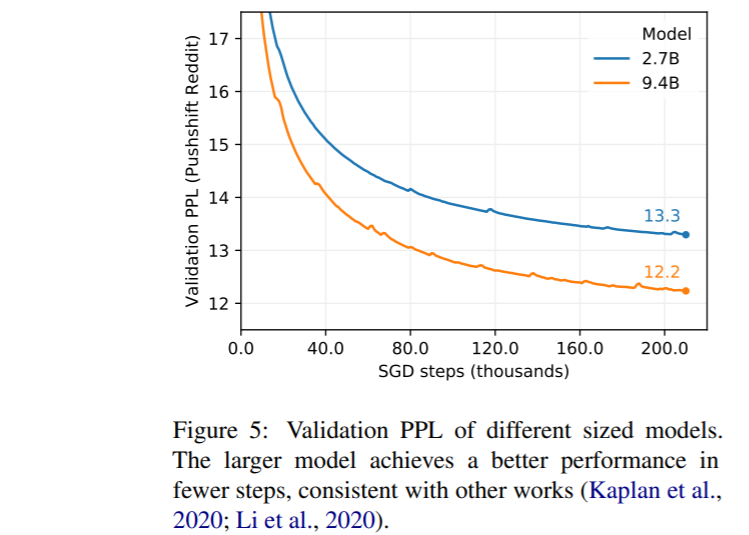
Generative Model은 3가지 크기로 만든 것을 확인할 수 있다. PPL은 성능지표이며 낮을 수록 좋은 성능을 의미한다. 당연하게도 90M 파라미터를 가진 모델보다 2.7B, 9.4B의 성능이 더 좋았다. 90M는 파라미터를 줄인 대신 Vocabulary size를 키웠다. 인코더의 갯수보다 디코더의 갯수를 훨씬 많이 쌓은 것도 눈여겨볼만하다.
Retrieve and Refine

Generative모델과 RetNRef모델을 함께 비교하였다. 각 데이터셋(ConvAI2, WoW, ED, BST)의 Validation set에대해서 평가를 하였고, 모델은 Reddit으로 pretrained만 된 모델과 BST로 fine-tuned된 모델을 비교하였다. 결과를 통해 모델의 파라미터를 키울 수록 성능이 좋아지는 것이 확인이 되었으며, Fine-tuning이 성능향상에 도움이 확실히 되었다는 것을 확인할 수 있다.
다만, Generative모델이 RetNRef보다 PPL이 약간 낮았던 것이 좀 의외이다. 논문에서는 다른연구(Weston et al. (2018))에서도 발견된 내용이며, 평과를 automatic evaluation으로만 하면 안된다고한다. 실제로 human evaluation에서는 RetNRef 모델이 더 좋았는데 본 포스트에서 후술한다.
Safety
유해단어를 필터링하는 것만으로는 유해한 발화를 피하기는 힘들었다. 유해발언을 검출하는 분류기를 따로 붙여 가능성은 많이 낮췄지만 그 위험은 여전히 남아있다.
2. Self-Chat Evaluations
Retrieval vs. Generator vs. Retrive and Refine

Generative Model, Retrieval Model, RetNRef Model에대해서 Human evaluations를 진행하였다. Retrieval모델이 Generative Model과 RetNRef모델보다 더 좋은 평가를 받았다. RetNRef 모델은 Generative모델을 60:40으로 이기긴했지만, Retrieval모델은 40:60으로 선택받지 못했다.
Generator Decoding Choices



앞선 포스트에서는 Generative Model이 갖고있는 문제점을 언급하였다. Figure 7은 생성하는 최소길이를 제한하는 것에대한 결과이다. Generator의 문제 중 짧은 대답을 선호하는 문제는 길이제한을 통해서 매우 성능이 좋아진 것으로 보인다. 통계적으로도 유의한 결과를 확인할 수 있었다.
반복적인 토큰을 생성하는 문제는 Beam blocking으로 해결을 시도하였고, 결과는 Figure 8을 통해 확인할 수 있다. 미세하게 좋았으나 기대만큼의 성과는 없어보인다.
Figure 9에대한 내용이다. 캡션으로 'None of these results are statiscally significant'라고 통계적으로 유의하지 않다고한다. 이렇게 Beam Search의 단점을 여러 방법으로 시도하여 고쳤지만, 결국 Top-k와 50:50이다. 구글이 Beam Search대신 선택한 Sample + Rank과 비교하면, 52:48로 선택받지 못한 비율이 더 많다. 결국 Beam Search보다는 Sampling으로 가는 것이 맞지않을까라는 생각이 드는 대목이다.
Small vs. Large models, Pre-training vs. Fine-tuning,
Persona context vs. No context given, Liklihood vs. Unlikelihood
| better | worse |
| Large (57) | Small (43) |
| Fine-tuning*(61) | Pre-training*(39) |
| Persona context (53) | No context given (47) |
| Unlikelihood (54) | Likelihood (46) |
작은모델보다는 큰 모델이, pre-training만 시킨 모델은 Fine-tuning된 모델이, Persona context가 주어진 모델이 context가 주어지지 않은 모델보다 성능이 더 좋았다. *가 된 것만이 통계적으로 유의한 차이가 있다. (Unlikelihood에서 기대를 많이 했는데, 큰 차이는 없었다. Sampling이 더 좋을까..)
Meena와의 비교
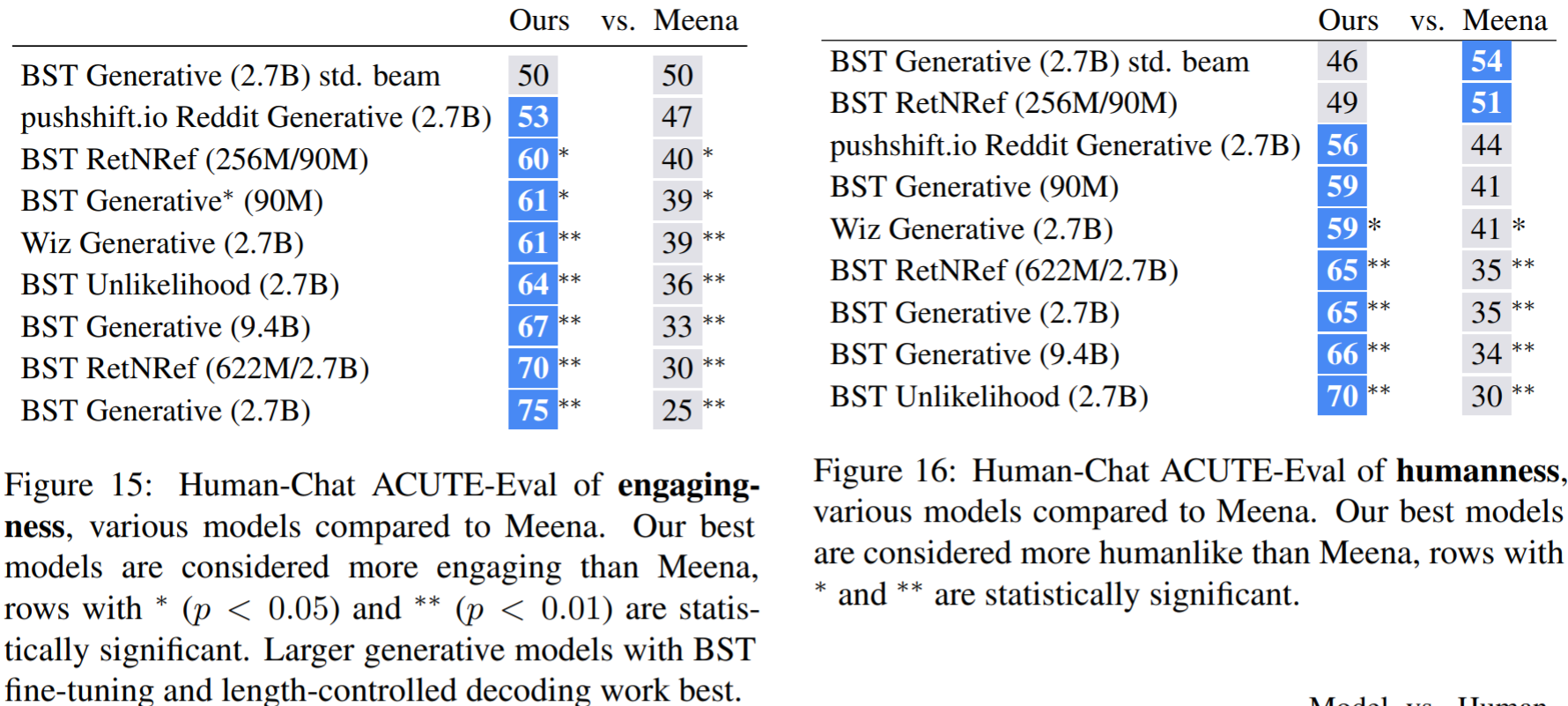
확실히 Meena를 의식을 많이했는지, Meena와 많이 비교하였다. 대부분의 모델이 통계적으로 유의한 차이로 Meena보다 본 연구에서 개발한 모델을 선택하였다.
사람과 비교

모델을 사람과도 비교하였다. 이부분은 굉장히 흥미로운데, Meena는 28%만이 선택을 받았다. 어쩌면 당연한 결과인데, BST 모델은 통계적으로 유의하지 않을 만큼 선택받았다. 즉 차이가 있다고 말할 수 없을만큼 선택을 많이 받은 것이다. 물론 사람을 이기지는 못했지만, 매우 재미있는 결과라고 생각한다.
Failure Cases and Model Extensions
성공적인 부분은 생략하고 실패한 부분을 간략하게 정리한다. 본 논문에서 필자는 ACUTE-eval (Human evaluation)에서 49:51이라는 결과를 냈지만 (바로 위의 결과, BST Generative (2.7B)), 이 결과를 믿지 않는다고한다.
- Vocabulary Usage


BeamSearch 기반의 decoding전략은, 흔한 단어가 너무 많이 나오게된다. 흔하지 않은 단어는 상대적으로 너무 나오지 않는 문제점을 갖고있다. 사람은 챗봇의 답변을 기술적으로 이해할 수 있지만, engaging하지 않는다는 문제를 갖고있는 것이다. 이러한 문제를 'I don't know' problem이라고한다.
위 Figure 22를 보면, Unlikelihood를 적용하여 훈련한 모델도 흔한단어(Do you have와 같은)를 사람보다 비정상적으로 많은 빈도로 대답한다. 그래도 MLE에 비해서 빈도를 확연히 줄여주는 효과를 볼 수 있었다. 하지만 Figure 17에서 확인해보면, Unlikelihood를 적용한 것이 오히려 Human Eval에 미세하게 부정적인 영향을 준 것을 확인할 수 있다. - Nontrivial Repetition
반복되는 문제가 여전히 남아있다. Beam Blocking으로 어느정도 막긴했지만, 예를 들어 개를 키운다고하면 챗봇도 개를키운다고하거나 산책좋아한다고하면 챗봇도 산책을 좋아한다고 하는 것이다. 그렇다고 페르소나를 무작정 추가한다면 경우의 수가 많기 때문에 좋은 방법인지는 불분명하다. - Contradiction and Forgetfulness
아들이 2명이었다고 했다가, 3명이었다고했다가, 손자가 3이라고하는 등 모순되는 말을 많이한다. (직접 배포된 모델을 사용해보니까 체감 상 가장 컸던 문제이다.) 이러한 문제를 Unlikelihood를 통해서 해결한다고 하는데, 나는 오히려 이 부분을 persona를 추가하는 방식으로 하는 게 낫지 않을까하는 생각이 들었다. - Knowledge and Factual Correctness
어떤 주제에 대해서 깊이 들어가게 된다면, 모델의 약점이 드러날 수 밖에 없다. 하지만 평가에서 이런 오류는 매우 드물다. 왜냐하면 평가방법의 특성 때문인데 '안녕'이라고 시작하는 초면의 대화이기 때문에 어떤 주제에대해서 심도깊게 다루기 쉽지 않기 때문이다. 또한, 모델은 어떤 주제에 깊이 들어가려고하면 주제를 바꾸는 경향도 있다. (상대를 알아가는 ConvAI데이터셋의 영향때문으로 보인다) Wikipedia를 직접읽음으로써 깊이있는 대화를 유도하는 모델도 만들었는데, ACUTE-eval에서 오히려 부정적인 평가를 받았다. - Conversation Length and Memory
평가는 매우 짧은 대화로 이루어져있고, 이전 대화를 기억할 수 조차 없다. 시도하지않았다. - Deeper Understanding
말을 정말 이해할 수 있는가? 아니다. 모순과 망각에서도 알 수 있지만, 말장난 같은 농담을 이해하지 못한다.
BlenderBot 2.0에서는 위 문제점들을 해결하기위한 노력들이 많이 보인다. 2.0으로 넘어가보자




댓글