
객체탐지 (Object Detection)
YOLO !! (v1~v3 간단리뷰)
YOLO

Joseph Redmon에 의해 개발된 YOLOv3는 Github에서 다크넷을 클론해서 쓰는 방식으로 굉장히 편리하게 사용할 수 있습니다. 구글 코랩에서도 쉽게 작동합니다.

YOLO가 정확하면서도 빠르다보니 군사목적으로 많이 사용이 되었는데, 이 때문에 더 이상 CV를 멈추신다는 글을 남기셨습니다. 논문도 굉장히 재밌고 유머러스하게게 쓰시던 분이었는데 안타깝습니다.

YOLO는 Alexey라는 분이 이어서 개발을 진행중이시고 이후에 나온 욜로도 성능이 굉장히 뛰어납니다. Github보시면 포크된 것을 볼 수 있고, v4는 이 곳에 업데이트 되어 있습니다. 물론 v3로 함께 사용할 수 있습니다.
YOLO v1

YOLO에서는 먼저 이미지를 받으면 가로로 7칸, 세로로 7칸씩 나눕니다. 한칸 한칸을 그리드 셀이라고 합니다. 각 그리드셀은 박스 두 개를 그리면서 구역을 예측하고 (위 Bounding boxes + confidence), 동시에 한 셀당 한 클래스에 대해서 예측합니다 (아래 Class probability map). 이 두 개가 동시진행 되고 합쳐져서 아웃풋이 텐서형태로 나오게됩니다.

YOLOv1 논문에 나온 그림인데 인풋은 448x448x3(RGB)으로 넣고, 여기서 7x7 커널로 필터를 64개를 만듭니다. Feature map이 64개가 쌓이는 거죠. stride를 2로 해서 반으로줄이고 (224가됩니다), 거기서 stride 2로 Maxpool을 합니다. 그럼 또 반으로 줄어 112가 됩니다. 쭉쭉 뽑아 내다가 마지막에 FC 2번 쓰면서 7x7x30 텐서를 만들어냅니다.

+ 중간에 1x1 이 나오는데 저는 왜 굳이 1x1 을 사용 하나 궁금해서 찾아봤습니다. 이 아키텍쳐를 디자인할 때, 구글 넷에서 영감을 많이 받으셨다고 합니다. 구글넷에서 보면 연산량을 줄이는 방법으로 1x1 커널을 사용합니다. 왼쪽에 원바이원 을 사용하지 않았을 때는 14x14x480에서 5x5 커널 이용하면 연산량이 1억 번이 넘습니다. 1x1 커널을 사용해서 진행한다면 526만인데요 연산량에서 엄청난 차이가 나죠. YOLO는 빠르기 위한 알고리즘 이기 때문에 이 기법을 차용한 것 같습니다.

다시 아키텍쳐로 돌아오면, 마지막에 7x7x30 나오는 것을 볼 수 있습니다. 앞에서 인풋 이미지를 7x7 그리드 셀로 나눴죠? 이 한칸한칸 30개의 값이 들어가 있는 겁니다.

좀 자세하게 30 하나씩 뜯어보면 다섯 개는 xywhc이고, 여기서 x y 는 오브젝트의 중점, 그리고 w h 는 오브젝트의
너비와 높이를 의미합니다. c는 Confidence 인데 오브젝트가 이 셀에 있을지 없을지를 나타내는 값입니다. 앞서서 한 셀당 두 개의 박스를 예측한다고 했었습니다.

그래서 한번 더 예측합니다! 박스를 하나 더 예측하는 거죠

논문에서는 클래스를 20개로 줬기 때문에 뒤에가 다 클래스입니다. 클래스 만큼 텐서가 추가됩니다.
여기서 잠깐 정리, 7x7x30을 하나 빼서 보면
($x_1$,$y_1$,$w_1$,$h_1$,$c_1$(첫 번째 박스 예측),$x_2$,$y_2$,$w_2$,$h_2$,$c_2$(두 번쨰 박스예측),
$class_1$,$class_2$,$class_3$, ... , $class_19$,$class_20$)으로 이루어지게 됩니다.
즉 앞의 10개의 값으로 박스 2개를 그린뒤 각각 박스의 confidenc(물체가 있을 확신)을 갖고, 뒤의 20개의 값으로 softmax를 이용해 어떤 클래스가 있을지 예측합니다.
Loss Function


위에 두 줄은 X Y W H에 해당하는 Loss입니다. 물체 중심을 잘 맞췄는지 물체 크기를 잘못 마췄는지에 해당하는 Loss function이고, 회귀문제이기 떄문에 squared error를 사용합니다. 아래 두줄은 Confidence, 물체가 셀 안에 있는지 없는지에 대한 Loss입니다. 마지막은 Classification에 대한 LOSS입니다
한계
여러가지 문제가 있었는데, 그중에 하나가 한 셀당 한 개 클래스 밖에 예측을 못 하는 문제와, 7x7로 나누나보니 앞의 문제와 합쳐져 작은 물체를 탐지 못하는 문제가 있었습니다.
YOLO v2

이후로 YOLOv2가 나왔고, YOLO 9000이라고 불리는데 9천개 클래스에 대해 예측을해보자해서 YOLO 9000이라고 이름 지어졌습니다. 성능향상은 오른쪽에 있는 거 사용하였습니다. v3와 중복되는 내용이 많으므로, 이 포스트에서는 몇 개만 간략히 살펴보고 넘어가겠습니다.

그리드 맵을 7x7에서 13x13으로 늘렸습니다. 작은 물체를 탐지할 수 있다는 뜻입니다. 그리고 버전 1에서 사용하지 않던 앵커박스를 사용하게 되는데 박스에 크기를 미리 정해 놓았습니다. 박스 크기는 각 데이터셋 별로 박스의 크기를 보고 K means clustering을 합니다. 굉장히 효율적인 방식이라고 할 수 있는데, 예를들어 영상에서 사람을 찾는다고 했을 때, 일반적으로 세로로 긴 형태의 박스를 가질 것 입니다. 즉, 각 데이터셋별로 앵커박스의 형태나 크기를 군집화를 통해서 정하는 것입니다. YOLOv2에서는 다섯 개를 사용했습니다. 한 그리드 셀당 다 크기가 정해진 박스를 다섯 개 를 사용하는 것입니다.

YOLOv2의 성능이 많이 개선된 걸 볼 수 있었습니다.
YOLO v3
구어체로 쓰여져있고, 딱딱하지 않은 글이라 재밌게 읽은 것 같습니다. arxiv.org/abs/1804.02767

레티나넷을 소개하는 논문에서 figure을 그대로 가져와서 yolo를 그 위에 그린 것입니다. 저자의 센스를 볼 수 있는 대목인 것 같습니다. 그만큼 빠르고 성능도 좋다는 것이겠죠.
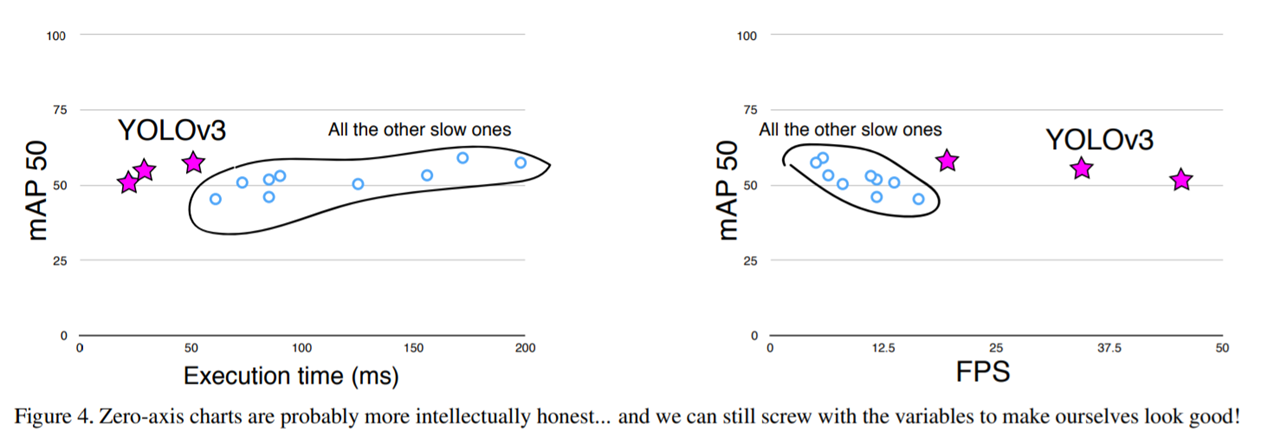
근데 항의가 들어왔는지 Rebuttal에서 0으로 시작하는 것을 다시 그렸습니다. 그럼에도 성능이 좋다는 걸 잘 어필하고 있습니다.

YOLOv2에서 사용한 Darknet-19 아키텍쳐와 v3에서사용한 Darknet-53입니다. 제가 여기서 가장 재밌었던건 Darknet-19 까지는 Maxpool을 사용했는데 Darknet-53에서는 사용하지 않습니다. 이게 뭘 의미하는 건지 생각해 보니까, Max Pooling은 다 죽이고 제일 큰 것만 갖고 오는데 stride를 쓰는 컨볼루션은 죽이지는 않고 갖고 옵니다. 다시 말하면 low level feature의 손실을 어느 정도는 방지하겠다라는 의미인것같습니다.

그리고 이제 더 이상 소프트맥스를 사용하지 않고 각각의 클래스에 대해서 예측을 하게됩니다. 이진분류 문제로 바뀌는거죠. 논문에서는 사람이면서 여자인 경우를 예로 들고있습니다. 멀티레이블 문제를 해결하기 위해서 이런식으로 바꿨다고 합니다.

그리드 셀에서 그리드셀 바깥으로 박스를 예측하지 못하도록 시그모이드를 취해줍니다. 그럼 0과 1사이로 바꿔주겠죠.다시말해 한 칸 이상 이동할 수 없게 만듭니다. 박스의 중점은 해당 그리드셀에 존재하도록 하게 만드는 것입니다.
Architecture

Darknet-53에서는 3개의 스케일에 대해서 예측을하게 됩니다. 앵커의 크기는 각 스케일마다 세 개씩 주어지게 되고요 한 그리드셀에 박스가 세개씩 생기는것입니다. 스케일이 작은 첫 번째 그림에서는 큰 물체를 인식하고 2번째 3번째로 가면서 점점 작은 물체를 예측하겠다라는 컨셉입니다. 업샘플링 할 때 skip connection을 하는데 레티나넷과 굉장히 유사합니다.

피쳐맵을 뽑아 낼 때마다 위치 정보에 대한 정보가 많이 손실이 됩니다. 이걸 다시 업샘플링 하면서 그 피처 맵에 위치 정보를 더 하는 방식으로 다시 갖고오는 방식으로 손실을 방지합니다. Darknet-53을 다시 보시면 업샘플링 할 때마다 이전 블록(Residual Block)에서 갖고 오는 게 보이죠.

앞서 말했듯이 한 개에 그리드 셀에서 각각의 스케일에 대해서 3개의 앵커박스가 주어집니다. 오른쪽을 예로 들었을 때, 코코데이터셋으로 훈련한 모델에서는 첫 번째 스케일에서는 앵커박스가 3개가 주어지고(116x90,156x198,373x326),
두 번째 스케일에서도 3개가 주어지고 (30x61,62x45,59x119),
세 번째 스케일에서도 이렇게 3개가 주어집니다(10x13,16x30,33x23).
왼쪽은 텐서 하나를 빼서본 그림입니다. 아래가 박스 하나에 대한 텐서인데, 초록색 부분이 오브젝트의
위치랑 크기에 대한 정보(박스)고 가운데가 물체가 있을지 없을지 에 대한 값인 Confidence , 오른쪽이 클래스에 대한 예측정보입니다. 이것이 박스하나에 대한 것이고, v3에서는 그리드셀당 박스3개씩 그린다고 했으니 한텐서에 박스 3개가 담기게 되는 것입니다.이 과정을 3번의 스케일에 걸쳐서 진행하게 됩니다.

정리하면 YOLOv1에서는 7x7인데 박스 2개만 예측했습니다. 그래서 98개 박스 밖에 없었는데, YOLOv2가되면서 K Means Clustering으로 각 그리드셀마다 5박스씩 예측을해서 845개 박스를예측합니다. YOLOv3가 와서는 3개의 앵커 박스가 각 스케일마다 3개의 앵커박스가 있으니까 박스가 10000개가 넘어갑니다. 정확하게 하기 위해서는 어쩔 수 없는 변화인 것 같습니다.
'인공지능 > CV' 카테고리의 다른 글
| GAN에서의 미분 (Pytorch) (0) | 2021.10.13 |
|---|---|
| YOLOv3를 이용한 턱스크찾기 프로젝트 (3) | 2021.05.01 |
| 객체탐지 (Object Detection) 1. YOLO 이전 까지 흐름 (0) | 2021.05.01 |
| MASK RCNN 실행시 버전오류 (0) | 2021.04.20 |
| [CODE] EfficientNetB7 (0) | 2021.04.10 |




댓글