CoCa: Contrastive Captioners are Image-Text Foundation Models
개요
BERT와 같은 사전학습된 large-scale pretrained foundation models 기반으로 자연어처리 분야에서 괄목할 발전을 이루어 냈습니다. 최근에는 CV에서도 문제를 해결해나가고 있습니다.
CoCa에서는 비전분야에서 적용할 수 있는 foundation models을 제안합니다. 해당 모델은 Representation learning에서 효과적인 성과를 내었던 Contrastive loss와 멀티모달 모델을 위한 Captioning loss를 적용하였습니다.
이렇게 훈련시킨 CoCa 모델은 CV 분야에서 다양한 Task(datasets)에 대해서 SOTA를 달성하였습니다.
기존의 연구들
(1) Vision Pretraining : Single encoder
2014년~2015년부터 Single encoder의 시대가 열렸습니다. Convolution 모델들에 cross entropy loss로 이미지 분류하는게 매우 효과적이었다는 것이 확인이 되었습니다. ImageNet과 같은 데이터셋으로 훈련시킨 모델은 general한 featutre를 잘 추출하는 것 처럼 보였고, 여러 downstream task에 transfer되어 사용되기도 했습니다다. 그러나 이런 모델들은 구조 상 사람의 자연어 형식으로 넘어갈 수 없는 형식입니다.
ConvNets(VGG,Resnet)이나 Transformer기반 모델(BEiT 등)이 있습니다. 주로 ImageNet과 같은 큰 규모의 annotation된 데이터셋을 통해 훈련을 했습니다.
(2) Vision-Language Pretraining
LXMERT, UNITER, ViLBERT 등이 있습니다. 대부분 Fast(er) RCNN을 통해 Visual representation을 뽑아서 Language Model과 결합시키는 퓨전모델식으로 발전했습니다.
(3) Image-Text Foundation Models : Dual encoder
최근의 연구들에서는 encoder를 2개 사용하는 Dual encoder연구가 활발하게 이루어지고 있습니다. 대표적인 성공 예로 CLIP이 있습니다. CLIP에서는 ‘web-scale’ 이미지-텍스트 쌍에서 contrastive loss로 훈련 시키는 것에대한 가능성을 보여줬습니다. vision-only embedding 뿐만아니라 텍스트에 대한 임베딩이 동일한 latent space에 담길 수 있다는 것을 의미합니다. 하지만 vision embedding과 text embedding에서 직접적으로 연결되는 요소가 없어서인지 VQA(Visual Question Answering)같은 task에 대해서는 잘 대처하지 못했습니다.
(3) Image-Text Foundation Models : Encoder - Decoder
최근 일련의 연구에서는 Image를 인코더에 넣고 디코더로 나온 output을 (Prefix) Language Model Loss에 적용하고있습니다. 대표적으로 SimVLM이 있습니다. 인코더에서 나온 이미지 어텐션이 텍스트 디코더에 직접적으로 영향을 미치는 구조입니다. 이에 관해서는 아래에서 설명을 덧 붙이겠습니다.
Approach
Single Encoder Classification
ImageNet과 같은 annotation된 데이터 셋이 필요합니다. 그리고 Annotation text는 보통 class의 이름으로 고정되어있다.
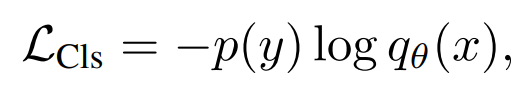
이러한 annotation은 보통 discrete class vector로 되어있어 cross entropy로 Loss를 구하는 것이 효과적이었습니다.. 이러한 방법으로 훈련 된 모델은 generic visual representation extractor로서의 역할이 가능했습니다.
Dual-Encoder Contrastive Learning
Single Encoder는 사람의 annotation이 필요했습니다. 그러나 인코더를 두개써서 web-scale로 비교하면 추가적인 어노테이션이 필요가 없습니다. 두 개의 인코더를 한 배치 내에서 constrastive learning을 하기 때문입니다.

N은 배치그기, sigma는 얼마나 scale할지 Temperature를 의미합니다. $x_i$ 는 $i$번째 pair의 image embedding이고, $y_j$는 $j$번째 pair의 Text embedding입니다.
여기서 사용된 Contrastive Loss는 Kaiming He 논문(Momentum Contrast for Unsupervised Visual Representation Learning)에서 그대로 가져온 것입니다. 단지 image에 대한 text, text에 대한 image로 constrastive loss를 구해주었습니다.

Momentum Contrast for Unsupervised Visual Representation Learning에서 사용된 Loss function
Encoder-Decoder Captioning
일반적으로 Encoder-Decoder 구조를 가진 모델은 Autoregressive한 Generative 접근방식을 많이 사용합니다. 대표적인 예로 Captioner가 있습니다.
Encoder는 이미지를 인코딩하여 이미지의 latent encoded feature를 출력한다고 생각할 수 있습니다. 디코더는 여기서 인코더에서 나온 feature를 활용하여 Text의 likelihood를 최대화 시킵니다. (Autoregressive Factorization)

디코더의 훈련 효율성을 위해 Teacher forcing을 수행했습니다.
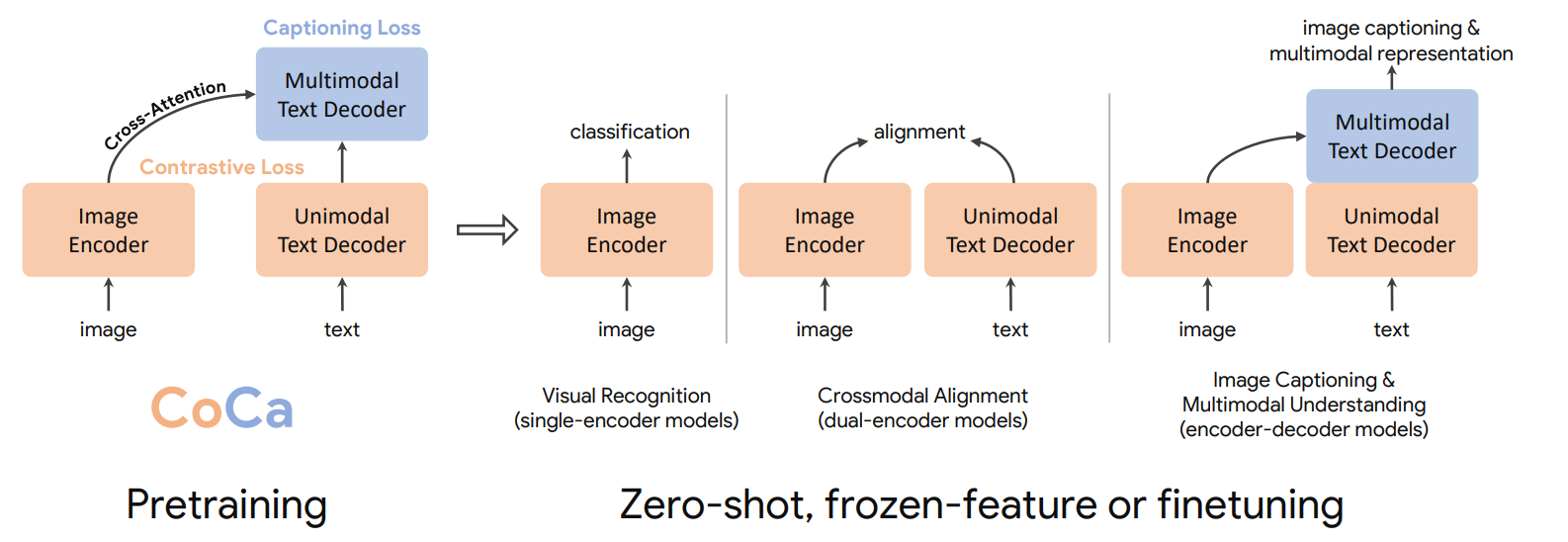
Contrastive Captioners Pretraining
CoCa는 Dual-Encoder Contrastive Learning과 Encoder-Decoder Captioning을 합친 방식이라고 할 수 있습니다. 한 모델 내에서 Contrastive Loss와 Captioning Loss를 구하고, lambda를 통해 가중을 정하는 것으로 손실함수를 정의했습니다.
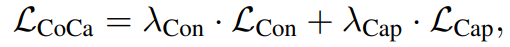
생각해보면 Capitioning loss는 텍스트의 conditional likelihood를 최적화시키기 위함이고, contrastive는 unconditional text representation을 최적화하기 위함입니다. 조건하에 텍스트 생성을 하는 것과 조건없이 그냥 대표성 학습을 하는 것이 동시에 이루어져야하는 딜레마를 안고 있습니다.

이러한 딜레마를 해결하기 위해 decoupled decoder를 제안합니다. 디코더 레이어들의 반은 텍스트만 받고(Unimodal Text Deocer), 나머지 반은 일반적인 트랜스포머처럼 인코더와 크로스어텐션을 줍니다(Multimodal Text Decoder).
Unimodal Text Decoder부분은 텍스트 자체에 대해 이해할 수 있는 레이어가됩니다. 즉, Text의 Representation을 학습하는 것입니다. Multimodal Text Decoder는 기존의 Captioning 모델처럼 이미지와 텍스트를 이해할 수 있는 레이어가 됩니다.
Unimodal Text Decoder에서 Representation을 뽑기위해 라는 스페셜 토큰을 추가하였습니다. CLS토큰은 해당 디코더를 통과하면서 Input 토큰들과 서로 어텐션을 주게되어, 입력된 문장 전체에 대해 Text embedding역할을 하게됩니다. 이 텍스트 임베딩은 이미지 임베딩과 비교하여 Contrastive Loss를 구합니다.
뒤의 Multimodal Text Decoder는 일반적인 생성모델방식으로 Generative Loss($L_{cap}$)으로 훈련시켰습니다.
Algorithm

Coca as image-text foundation models
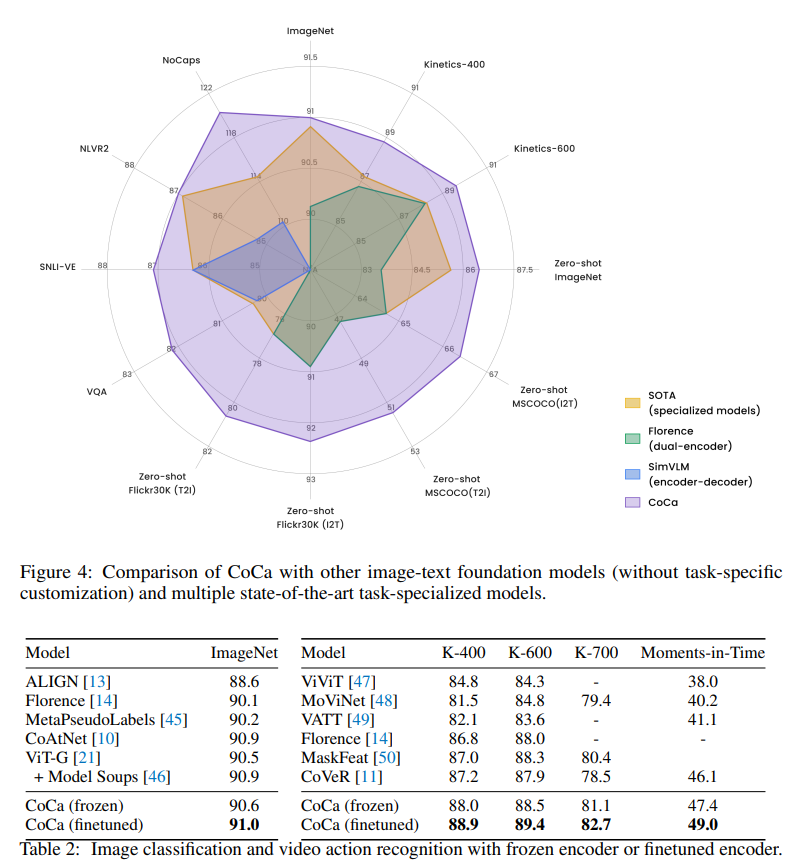
Reuslts
'인공지능 > CV' 카테고리의 다른 글
| [논문리뷰]CLIP : Learning Transferable Visual Models From Natural Language Supervision (0) | 2022.07.01 |
|---|---|
| [논문리뷰]Dall-E : Zero-Shot Text-to-Image Generation (0) | 2022.07.01 |
| 인공지능이 만드는 폰트 [ HAN2HAN : Hangul Font Generation] (0) | 2021.11.13 |
| GAN에서의 미분 (Pytorch) (0) | 2021.10.13 |
| YOLOv3를 이용한 턱스크찾기 프로젝트 (3) | 2021.05.01 |




댓글