반응형
4.1 평균, 분산, 표준편차 (numpy와 pandas의 ddof 디폴트값 차이)
def myfunc(data) :
mean = np.sum(data)/len(data)
var = np.sum([np.power(i - mean,2) for i in data])/len(data)
std = var**0.5
return mean, var, std
data0 = np.array([243, 278, 184, 249, 207])
data_panda = pd.DataFrame(data0)
x,y,z = myfunc(data0)
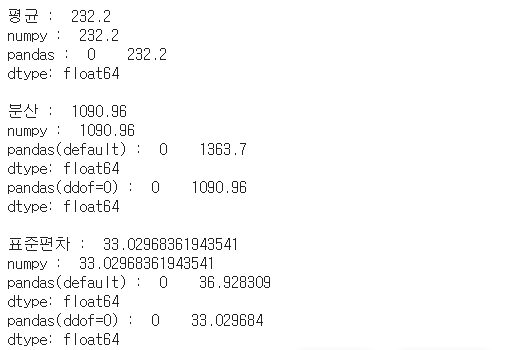
print('평균 : ',x,
'\nnumpy : ',data0.mean(),
'\npandas : ',data_panda.mean(),
'\n\n분산 : ',y,
'\nnumpy : ',data0.var(),
'\npandas(default) : ',data_panda.var(),
'\npandas(ddof=0) : ',data_panda.var(ddof=0),
'\n\n표준편차 : ',z,
'\nnumpy : ',data0.std(),
'\npandas(default) : ',data_panda.std(),
'\npandas(ddof=0) : ',data_panda.std(ddof=0))
4.2 Scattering으로 시각화
import pandas as pd
data1 = [216,32,50,302,40]
data2 = [320,420,60,50,20]
data = pd.DataFrame({'data1':data1, 'data2':data2})
plt.scatter(data.data1, data.data2)
plt.show()
4.3 공분산과 상관계수 구하기
mean_1 = np.sum(data1)/len(data1)
mean_2 = np.sum(data2)/len(data2)
var_1 = np.sum([np.power(i - mean_1,2) for i in data1])/(len(data1)-1)
var_2 = np.sum([np.power(i - mean_2,2) for i in data2])/(len(data2)-1)
std_1 = var_1**0.5
std_2 = var_2**0.5
covar = sum((data1-mean_1)*(data2-mean_2))/(len(data1)-1)
corre = covar / (std_1*std_2)
###
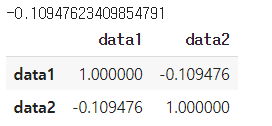
print(covar)
data.cov(ddof=1)
###
print(corre)
data.corr()
4.4 공분산과 상관계수 구하기 2
import seaborn as sns
tips = sns.load_dataset('tips')
tips.head()
fig, axes = plt.subplots(1, 3, figsize=(10,5))
axes[0].scatter(tips.total_bill,tips.total_bill, c = 'blue', alpha = 0.3)
axes[0].set_title("Total_bill & total_bil",fontsize=20)
axes[1].scatter(tips.total_bill,tips.tip, c = 'red', alpha = 0.3)
axes[1].set_title("Total_bill & tip",fontsize=20)
axes[2].scatter(tips.total_bill,tips['size'], c = 'blue', alpha = 0.3)
axes[2].set_title("Total_bill & size",fontsize=20)
plt.show()
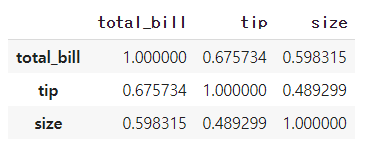
tips.cov()

반응형
'기본소양 > 선형대수학' 카테고리의 다른 글
| 파이썬으로 하는 선형대수학 (6. Clustering) (0) | 2021.01.19 |
|---|---|
| 파이썬으로 하는 선형대수학 (5. Dimensionality Reduction) (0) | 2021.01.19 |
| 파이썬으로 하는 선형대수학 (3. Span, Rank, Basis, Projection) (0) | 2021.01.18 |
| 파이썬으로 하는 선형대수학 (1. 스칼라와 벡터 & 2. 매트릭스) (0) | 2021.01.18 |
| [선형대수학] 차원을 왜 축소시키는가 (0) | 2021.01.15 |




댓글